使用自动化工具调参¶
这里我们以 GRU 为例,使用 LibCity 中提供的自动化调参工具(hyper_tune.py)优化其在 METR_LA 数据集上的交通速度预测性能。
首先,我们可以查看 GRU 在交通速度预测任务中可能会使用到的超参数,以决定要对哪些参数进行调整。
查看相关参数¶
根据 /libcity/config/task_config.json 查看 GRU 在交通速度预测任务下使用到的各个模块。
"GRU": {
"dataset_class": "TrafficStatePointDataset",
"executor": "TrafficStateExecutor",
"evaluator": "TrafficStateEvaluator"
}
根据配置文件可知,GRU 所使用的数据模块类为 TrafficStatePointDataset,执行模块类为 TrafficStateExecutor,评估模块类为 TrafficStateEvaluator。我们可以根据查找到的模块类名去 /libcity/config/ 具体模块配置的文件夹下,找到对应模块的详细超参数配置。
这里,我们认为对模型性能影响较大的是执行模块与模型本身的超参数。因此,我们查看了 /config/executor/TrafficStateExecutor.json 与 /config/model/traffic_state_pred/GRU.json两个配置文件。在查看过后,我们决定对学习率 learning_rate,最大训练轮次 max_epoch,隐藏层维度 hidden_size,Dropout 率 dropout 四个超参数进行调整。
编写调参配置文件¶
hyper_tune.py 脚本需要用户编写一个调参配置文件,以指定所要调整的超参数与对应的搜索空间。根据所要调整参数的意义,我们将搜索空间设定为:
对于学习率参数,一般应该是
0.01或者0.05这种以 1 或 5 结尾的值。因此,其对应的搜索空间应该是离散的类别变量集合,以[0.01, 0.005, 0.001]为例。对于最大训练轮次,其值应该是一个整数。因此,其对应的搜索空间可以设置为服从
U(2, 10)均匀分布的整数空间。对于隐藏层维度参数,其需要是整数而且一般是能够被 10 整除的值。因此,其对应的搜索空间应该与学习率参数一样,以
[50, 100, 200, 500]为例。对于 Dropout 率,其应该是
[0,1)之间的浮点数。因此,其对应的搜索空间可以为服从U(0.1, 0.6)均匀分布的实数空间。
根据上述设计,我们可以撰写如下的配置文件 sample_space_file.json:
(该文件应存放于项目根目录,与
hyper_tune.py同级)更多的参数空间信息可以参考文档。
{
"learning_rate": {
"type": "choice",
"list": [0.01, 0.005, 0.001]
},
"max_epoch": {
"type": "randint",
"lower": 2,
"upper": 10
},
"hidden_size": {
"type": "choice",
"list": [50, 100, 200, 500]
},
"dropout": {
"type": "uniform",
"lower": 0.1,
"upper": 0.6
}
}
执行 hyper_tune.py¶
在确保 sample_space_file.json 被正确放置于项目根目录后,我们便可以运行如下脚本进行自动调参了:
python hyper_tune.py --task traffic_state_pred --model GRU --dataset METR_LA --space_file sample_space_file
运行以下指令后,脚本会自行从搜索空间中采样对应的参数值,并进行模型的训练与验证,并在搜索采样组合验证完成之后,在终端输出最好的参数组合。
(目前脚本只支持以模型在验证集上的 loss 作为性能评估标准)
关于脚本的更多命令行参数,可以参见文档。
下图为运行过程的截图:
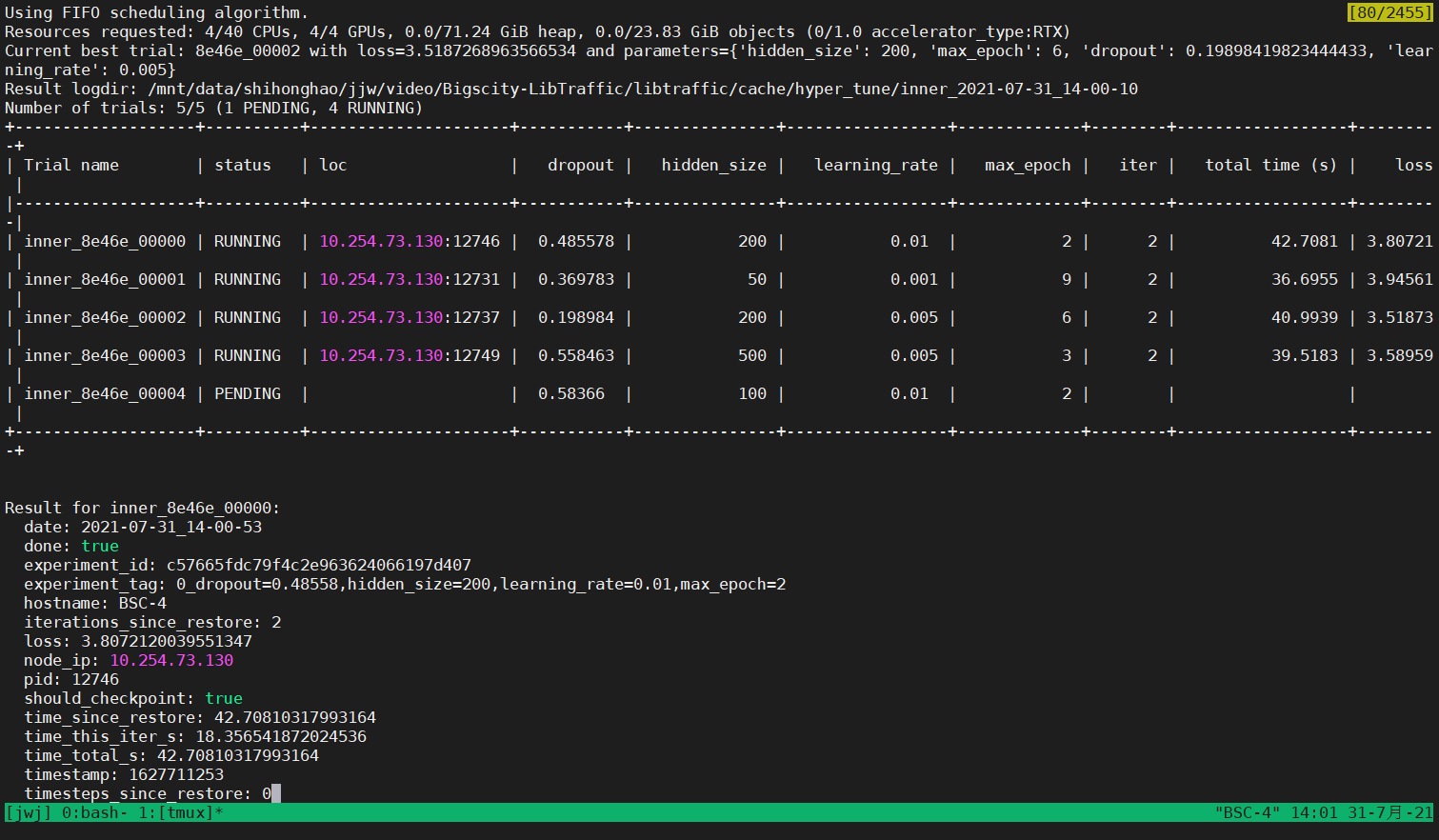
程序会将所采样到的参数组合输出至终端,并显示各线程的运行状态。
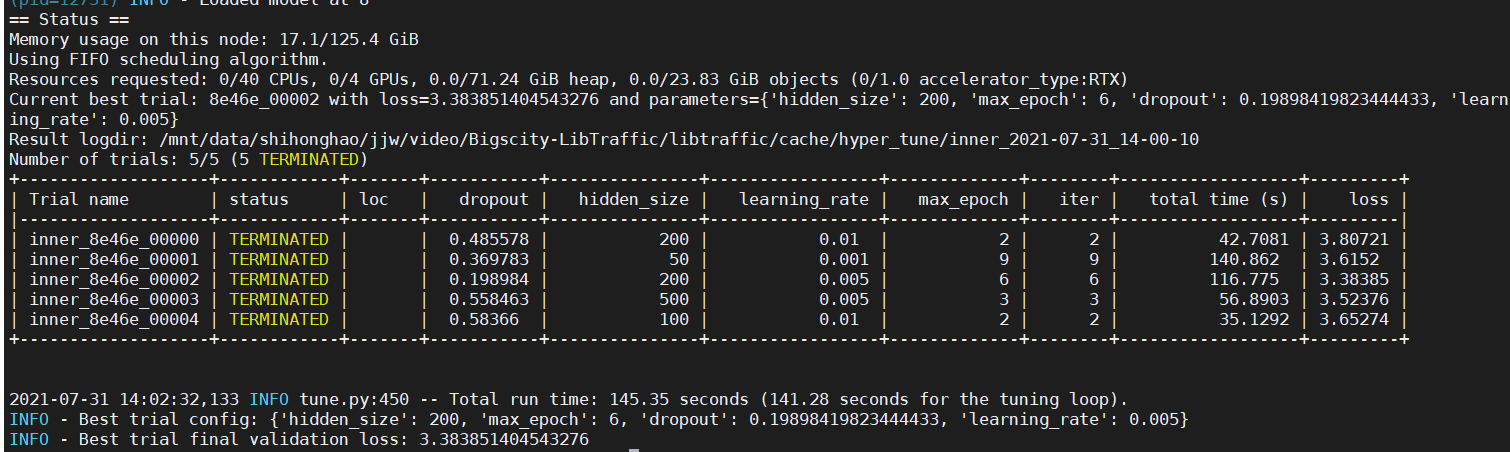
程序会将最好的参数组合输出至终端。